2026 ISSCC大会亮点:HBM4突破、LPDDR6登场,NVIDIA等巨头技术解析
每年全球有三大半导体盛会:IEDM、VLSI和ISSCC。过去几年我们已详细报道过前两个会议,今天终于完成这”三巨头”的拼图,为您带来ISSCC 2026大会的精彩内容。
相比IEDM和VLSI,ISSCC更聚焦于芯片集成与电路设计。几乎所有论文都包含电路图,并配有清晰的实测数据。
往年ISSCC的研究成果对产业的影响时好时坏,但今年不同——大量论文和演示直接关联市场趋势。涵盖领域从HBM4、LPDDR6、GDDR7和NAND的最新进展,到共封装光学(CPO)、先进芯片互连接口,以及联发科、AMD、英伟达和微软等巨头处理器技术。
本文将重点关注四大核心领域:存储器、光网络、高速电气互连和处理器。
存储器技术革新
本届ISSCC最受瞩目的主题当属存储器,包括三星的HBM4、三星和SK海力士的LPDDR6,以及SK海力士的GDDR7。除DRAM外,逻辑基SRAM和MRAM也引发广泛关注。
三星HBM4(论文15.6)
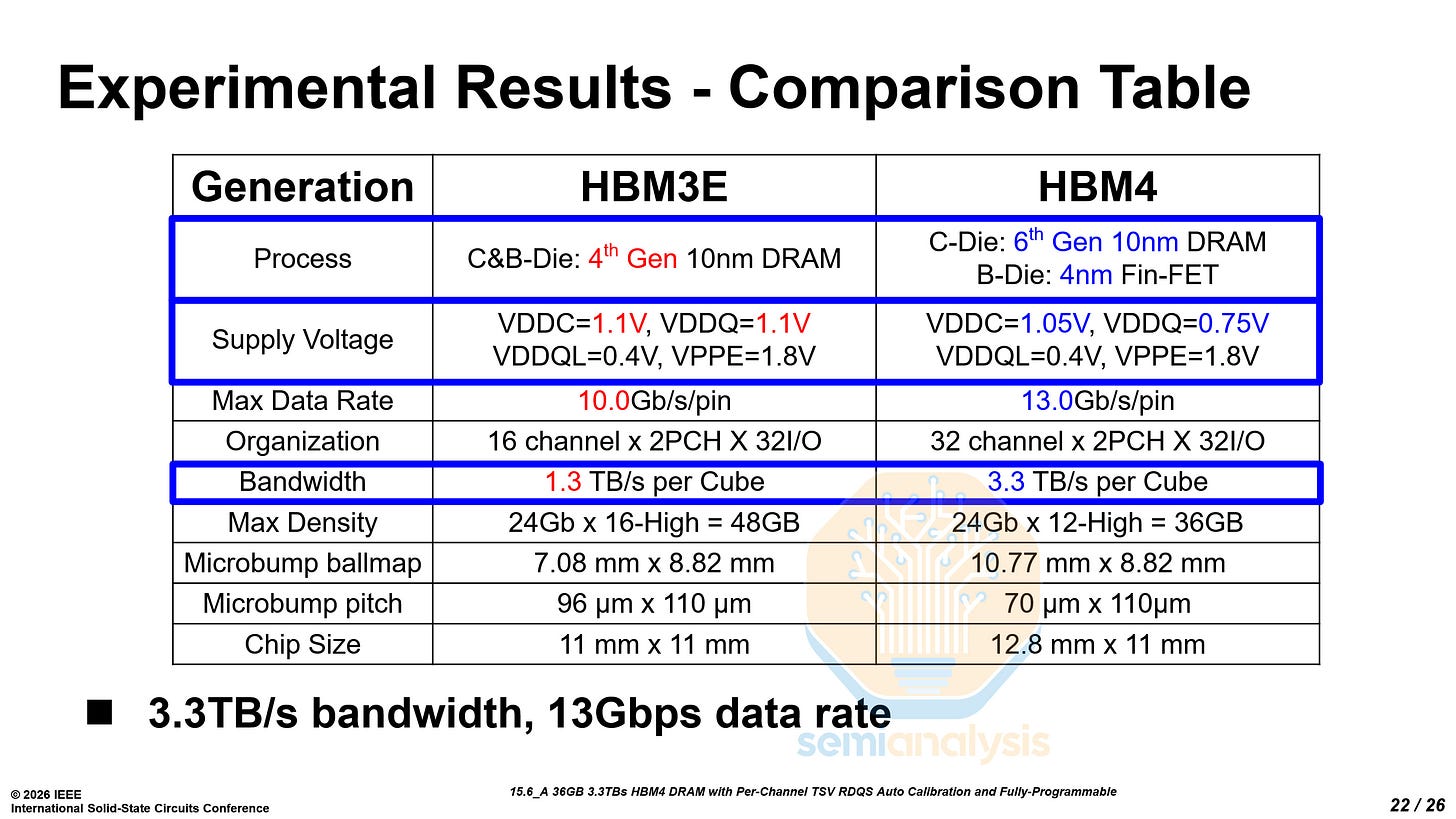
在三大存储巨头中,三星是唯一在ISSCC展示HBM4技术论文的公司。会前我们的加速器与HBM模型已指出,三星在HBM4代相比HBM3E取得巨大进步。ISSCC公布的数据印证了我们的分析——三星展示了行业领先的性能,我们早在几个月前的模型更新报告中就详细说明过这一进展。
ISSCC展示的技术细节结合我们收集的行业信息,清晰表明三星HBM4已具备与竞品抗衡的实力。尤其值得注意的是,它在低于1V电压下即可满足Rubin所需的引脚速度。尽管三星在可靠性和稳定性方面仍落后SK海力士,但技术差距已显著缩小,有望挑战SK海力士在HBM领域的主导地位。其采用SF4逻辑基底的1c工艺HBM4,在引脚速度上表现更优。
三星展示了36GB容量、12层堆叠的HBM4,配备2048个I/O引脚,带宽达3.3TB/s,采用第六代10nm级(1c)DRAM核心芯片与SF4逻辑基底芯片的组合。
从HBM3E到HBM4最显著的变化在于核心DRAM芯片与基底芯片的工艺分离。HBM4仅核心芯片沿用DRAM工艺,而基底芯片采用先进逻辑工艺——这与前代HBM使用统一工艺形成鲜明对比。
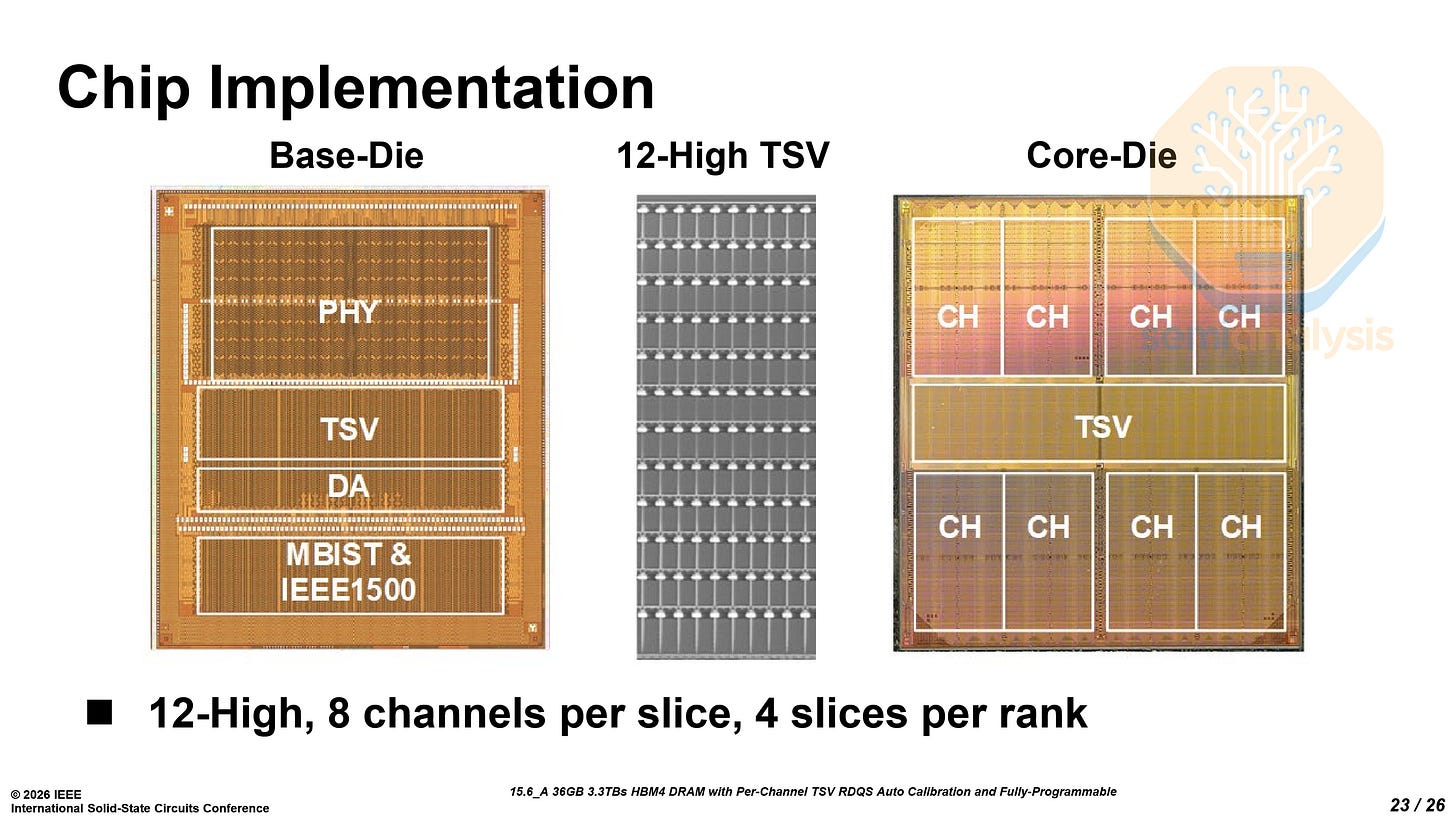
随着AI工作负载对HBM带宽和速率要求不断提高,三星将基底转向SF4逻辑工艺,实现了更高运行速度和更低功耗。工作电压(VDDQ)从HBM3E的1.1V降至HBM4的0.75V,降幅达32%。逻辑基底提供更高晶体管密度、更小器件尺寸和更优面积效率(得益于更小晶体管和更多金属层堆叠),帮助三星HBM4不仅达到——甚至大幅超越——JEDEC的HBM4标准(详见本节末尾说明)。
结合自适应体偏置(ABB)控制技术(可缓解堆叠核心芯片间的工艺偏差),以及TSV数量翻倍进一步改善时序余量。三星论文称,ABB和4倍更高的TSV数量使其HBM4引脚速度可达13Gb/s。
采用SF4基底和1c核心工艺带来性能提升的同时,也面临成本挑战。三星选择SF4逻辑基底的成本更高,尽管三星晶圆厂可提供内部使用折扣。SK海力士采用台积电N12逻辑工艺,美光则依赖其内部CMOS基底技术,这两种方案成本均低于近领先的SF4节点(即使考虑垂直整合成本优势)。
2025年三星1c前段工艺面临挑战,尤其考虑到公司跳过1b节点,直接从1a工艺的HBM3E升级到1c。去年1c节点前段良率仅约50%,虽逐步改善,但较低良率对其HBM4利润构成风险。
历史数据显示,三星HBM利润率长期低于主要竞争对手SK海力士,这一动态在我们的存储器模型中有全面体现。模型详细分析了各厂商HBM、DDR和LPDDR在不同节点的晶圆量、良率、密度、成本等数据。
三星的策略似乎是通过激进采用更先进节点的基底芯片来获得卓越性能,超越竞争对手——尤其当来自英伟达等领先客户的HBM要求日益严苛时。
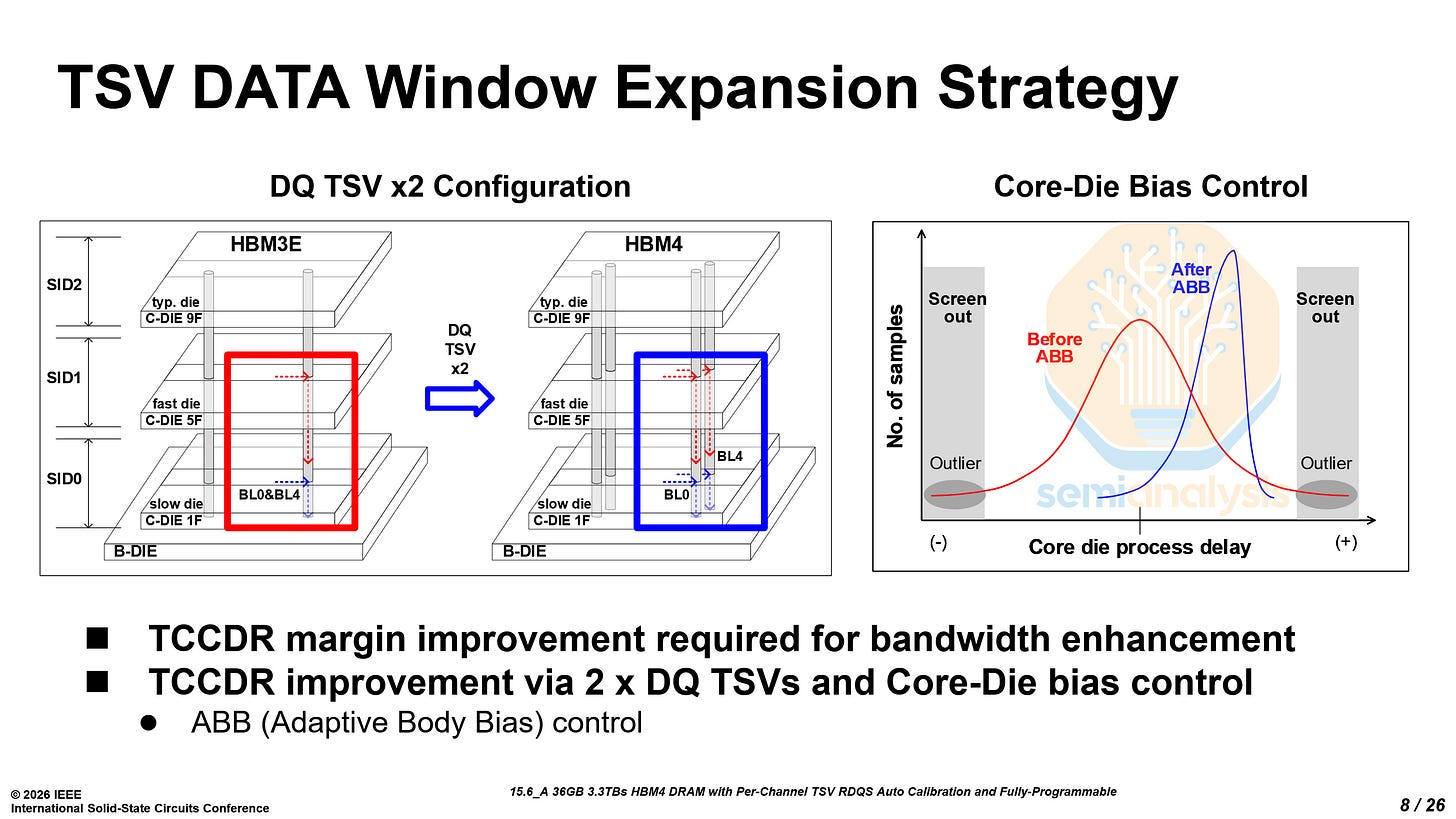
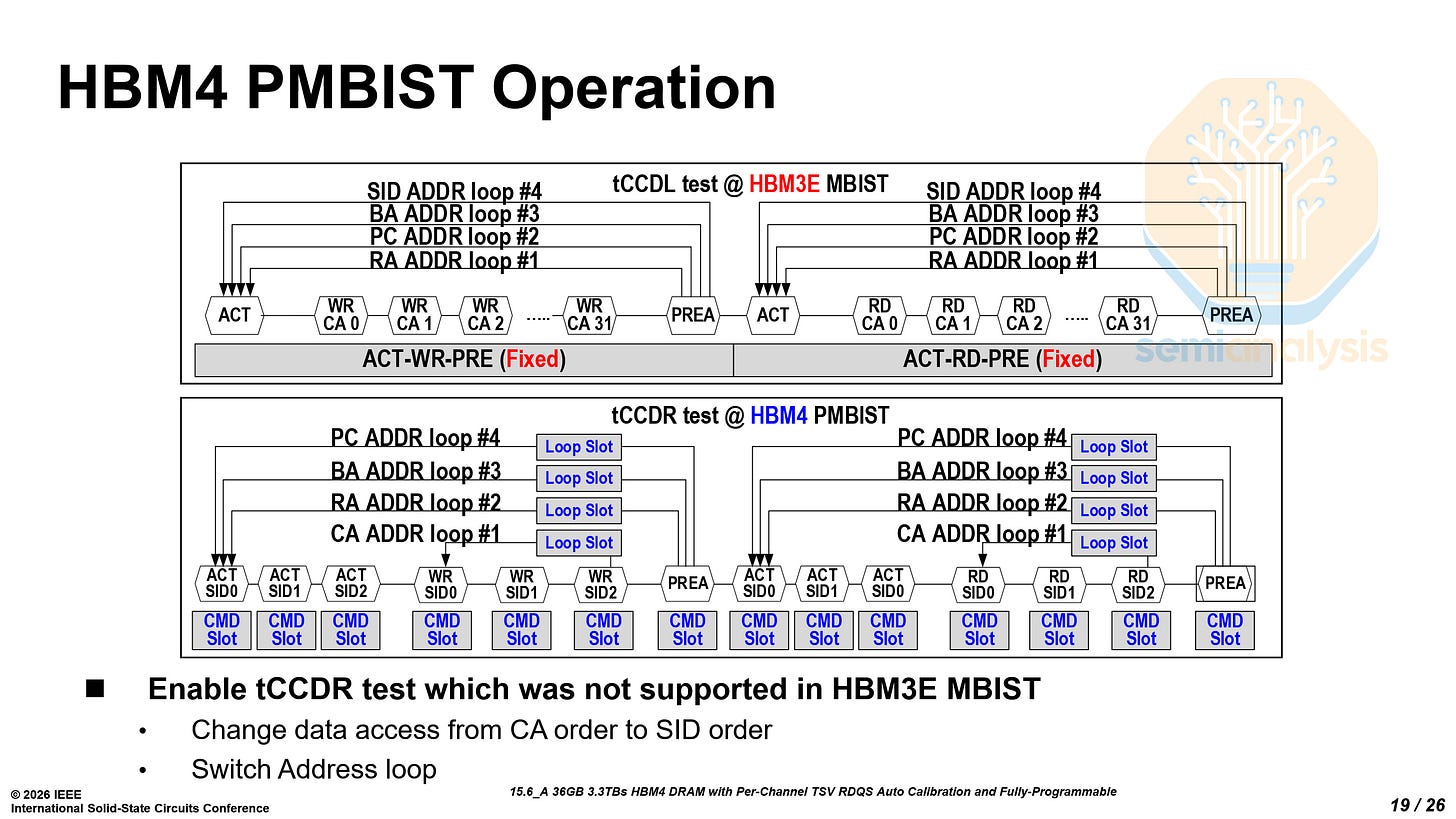
另一个关键挑战是tCCDR(跨不同堆叠ID连续读取命令的最小间隔)。对于依赖多通道并行内存访问的AI工作负载,tCCDR直接影响内存吞吐量。
在堆叠DRAM架构中,多个核心芯片垂直集成于基底芯片之上。这自然引入堆叠内微小延迟差异,源于核心芯片与基底芯片间的工艺偏差、TSV传播差异和局部通道变化。
堆叠高度从16增至32层、通道数增加,进一步加剧了这一挑战。随着通道数和堆叠高度增加,芯片间偏差累积,导致更大时序失配,影响可实现的tCCDR和整体HBM性能。
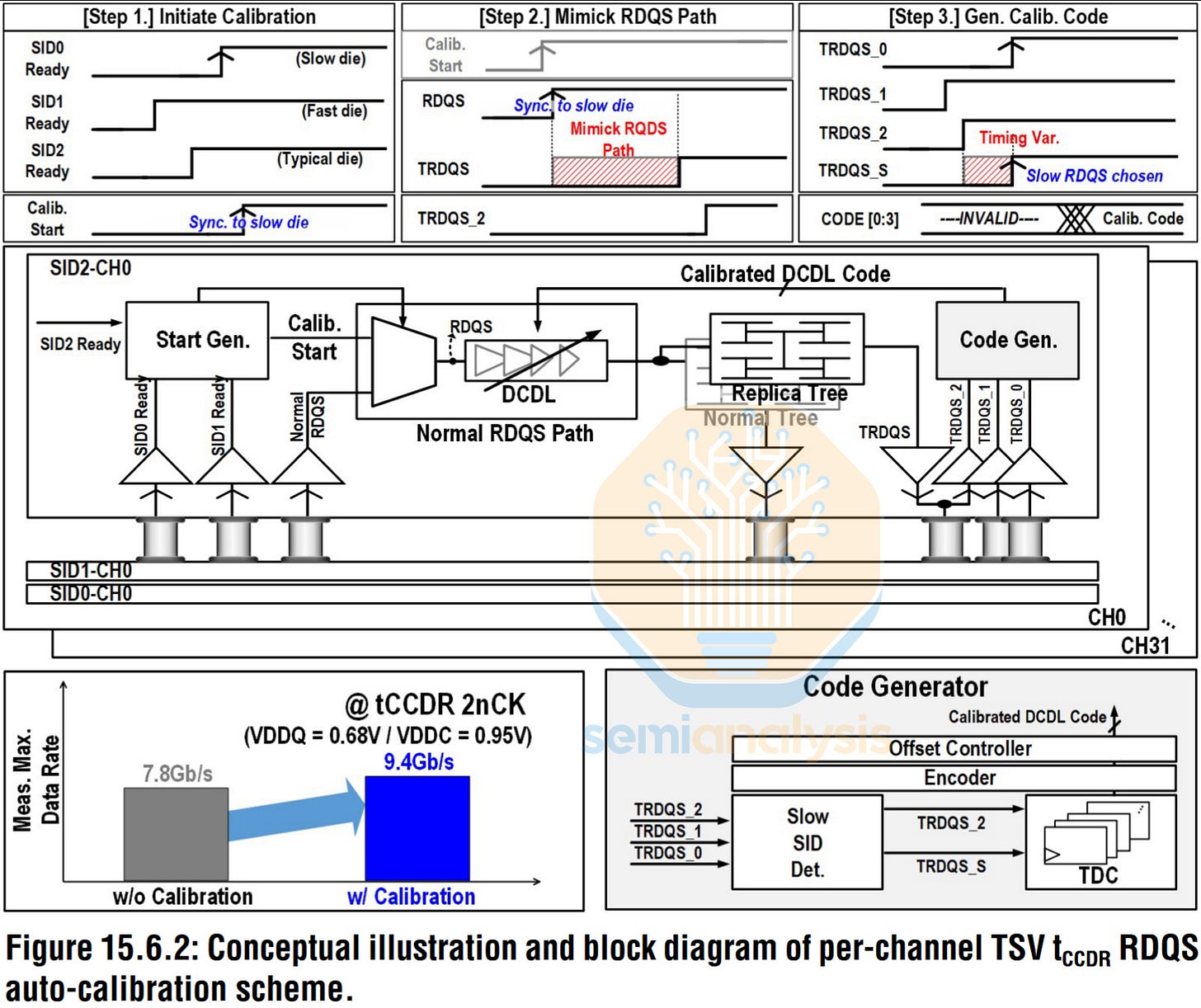
为解决此问题,三星推出”每通道TSV RDQS时序自校准方案”。系统启动后,通过复制RDQS路径(模拟真实信号路径时序行为)测量通道间延迟差异。时间-数字转换器(TDC)量化时序偏差,再通过每通道的延迟补偿电路(DCDL)进行补偿。
该方案同时处理核心芯片间的全局延迟偏差和局部通道偏差,实现堆叠内时序同步。通过补偿这些失配,三星显著提升有效时序余量,在满足tCCDR约束的同时提高最大数据速率——仅此一项就将数据速率从7.8Gb/s提升至9.4Gb/s。
熟悉存储技术的读者可能会问:如何为TSV数量激增预留足够芯片面积?这正是1c工艺的关键价值。相比前代1a工艺,1c进一步缩小DRAM单元面积,释放出集成HBM4所需更多TSV的空间。
三星LPDDR6与SK海力士GDDR7
三星展示了其LPDDR6技术,采用1.1V工作电压和32位接口,在1.1V下实现7.2Gb/s速率,功耗效率达5.5pJ/bit。而SK海力士则展示了GDDR7技术,采用24Gbps速率和384位接口,功耗效率低至1.8pJ/bit。
逻辑基SRAM与MRAM
除主流DRAM外,逻辑基SRAM和MRAM也取得突破。逻辑基SRAM通过优化晶体管结构提升密度和性能;MRAM则因其非易失性和高耐久性,在边缘计算和物联网领域展现潜力。
光网络与高速互连
NVIDIA与博通共封装光学(CPO)
英伟达和博通展示了CPO技术的最新进展。通过将光学器件直接封装在GPU或交换芯片旁,CPO大幅降低功耗和延迟,提升能效比。英伟达的方案采用硅光技术,而博通则专注于集成激光器解决方案。
台积电Active LSI技术
台积电推出Active LSI(大型系统集成电路)技术,通过在先进封装中集成主动电路,实现异构芯片间高效通信。该技术支持Chiplet设计,提升系统性能并降低成本。
UCIe-S接口标准
UCIe-S(超高速芯片互联标准)成为关注焦点。新标准通过优化电气接口和协议,支持更高带宽和更低延迟的Chiplet互联,为多芯片系统提供标准化解决方案。
处理器技术演进
联发科、AMD、英伟达和微软展示了先进处理器架构:
- 联发科:展示针对AI优化的定制CPU核心,提升能效比
- AMD:推出新一代APU,整合CPU与GPU,支持混合计算负载
- 英伟达:发布Blackwell架构GPU,采用先进封装和高速互连
- 微软:展示Azure Maia AI加速器,专为云端AI推理设计
这些处理器共同特点是:更强的AI算力、更高的能效比,以及支持更先进的互连技术。
总结
ISSCC 2026展现了半导体技术的多维度突破。存储领域HBM4和LPDDR6的性能跃升,光网络CPO技术的成熟,高速互连UCIe-S标准的推进,以及处理器架构的持续创新,共同推动行业向更高性能、更低功耗方向发展。三星在HBM4上的激进策略、台积电的Active LSI技术,以及各大厂商对Chiplet设计的投入,预示着2026年半导体产业将迎来新的技术浪潮。
原文链接:https://newsletter.semianalysis.com/p/isscc-2026-nvidia-and-broadcom-cpo
关注微信号:智享开源 | 关注微博:IMCN开源资讯网 ,可及时获取信息
为你推荐





还没有任何评论,你来说两句吧!