AI编程助手大盘点:谁能成为新霸主?
自从2月5日我们提到Claude Code的关键转折点以来,各种新模型如雨后春笋般涌现。Opus、Mythos、Codex、Gemini、DeepSeek、Kimi、Qwen、GLM、MiniMax、Composer、Muse Spark等等,让人眼花缭乱。今天我们就来深入解析这些主流模型,聊聊跑分数据到底能不能信,并预测一下AI智能编程市场的未来。
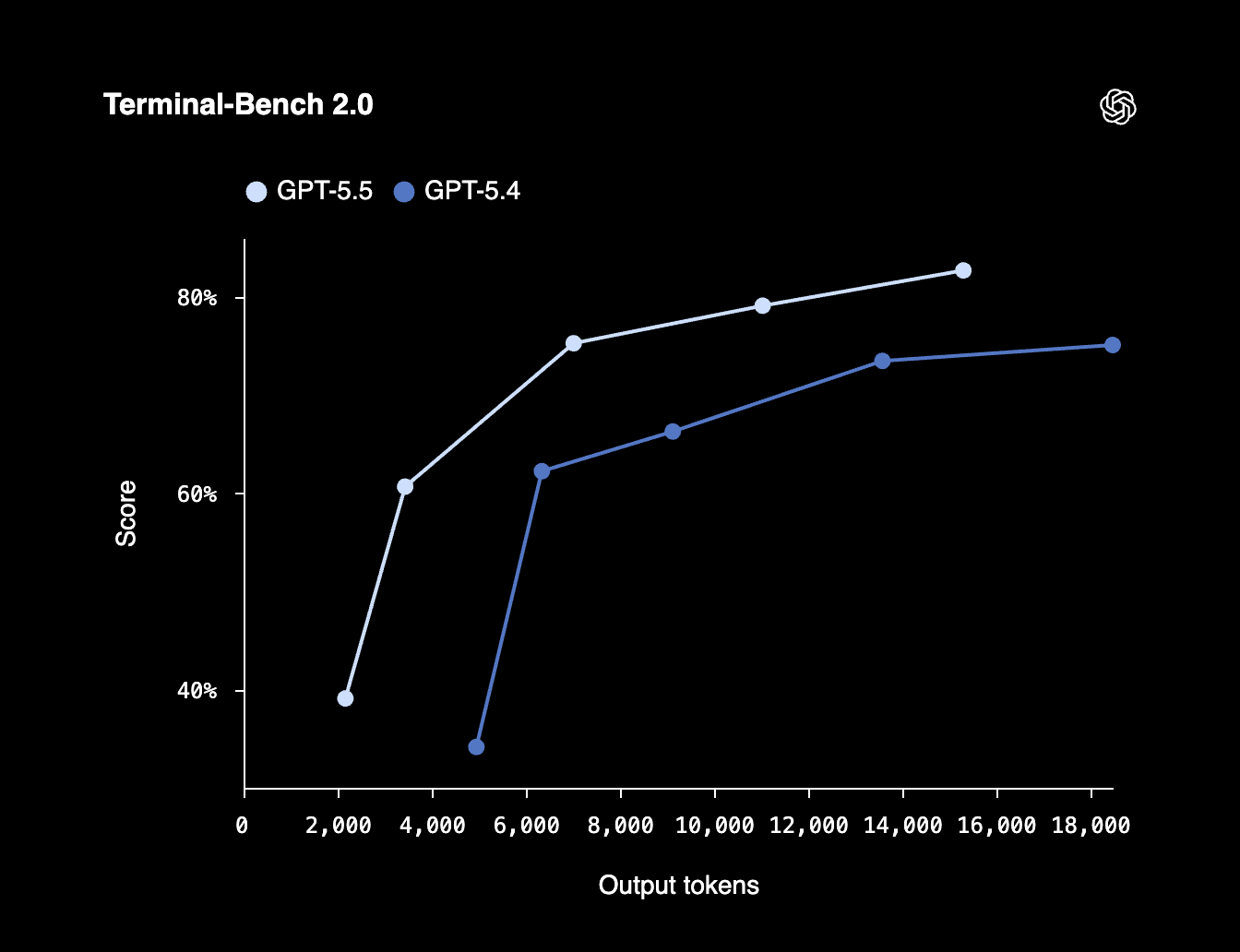
首先不得不提OpenAI的GPT-5.5。在我们看来,它在某些任务上已经明显优于其他所有模型,可以说已经处于行业最前沿。这与去年11月Opus 4.5发布时的情况大不相同。那时,以及随后的半年里,OpenAI的编程模型在各项指标上都算不上世界顶尖,导致我们那时首选Opus作为日常工作工具。但现在,GPT-5.5已经成功融入了我们的日常。
认识这些新模型
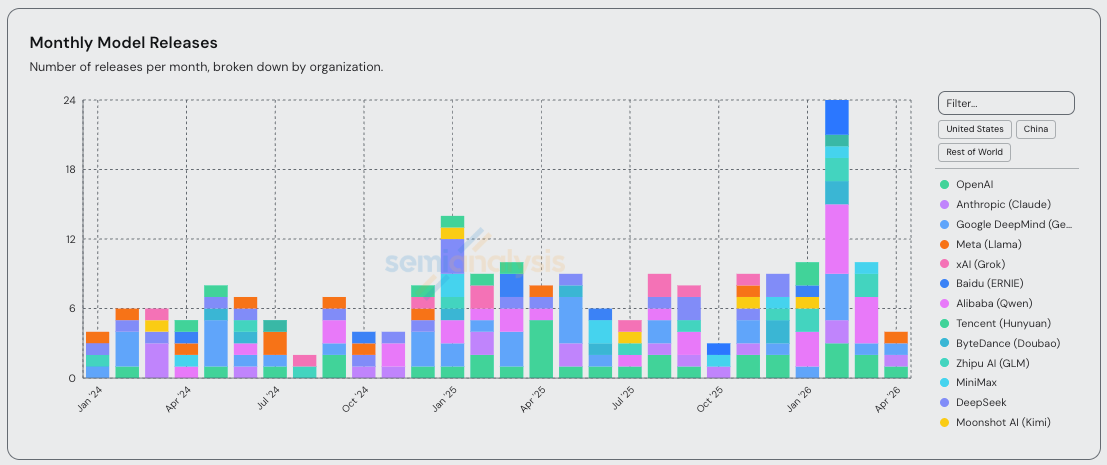
在过去3个月里,几乎每周都有大厂发布专门为编程优化的新版本。GLM-5.1、Qwen3.6-Plus、Kimi K2.6、Composer 2和Gemini 3.1 Pro都在宣传中强调了“代理编程”、“长周期任务”或类似的能力。尤其是2月份,发布节奏非常快。
虽然优化版本不错,但真正的全新基础模型才更让人兴奋。进入4月,旧金山到处都在传言关于“Capybara”和“Spud”的消息,这是Anthropic和OpenAI最新基础模型的代号。随着昨天GPT-5.5的发布,我们终于有了具体可聊的内容。
GPT 5.5 深度解析
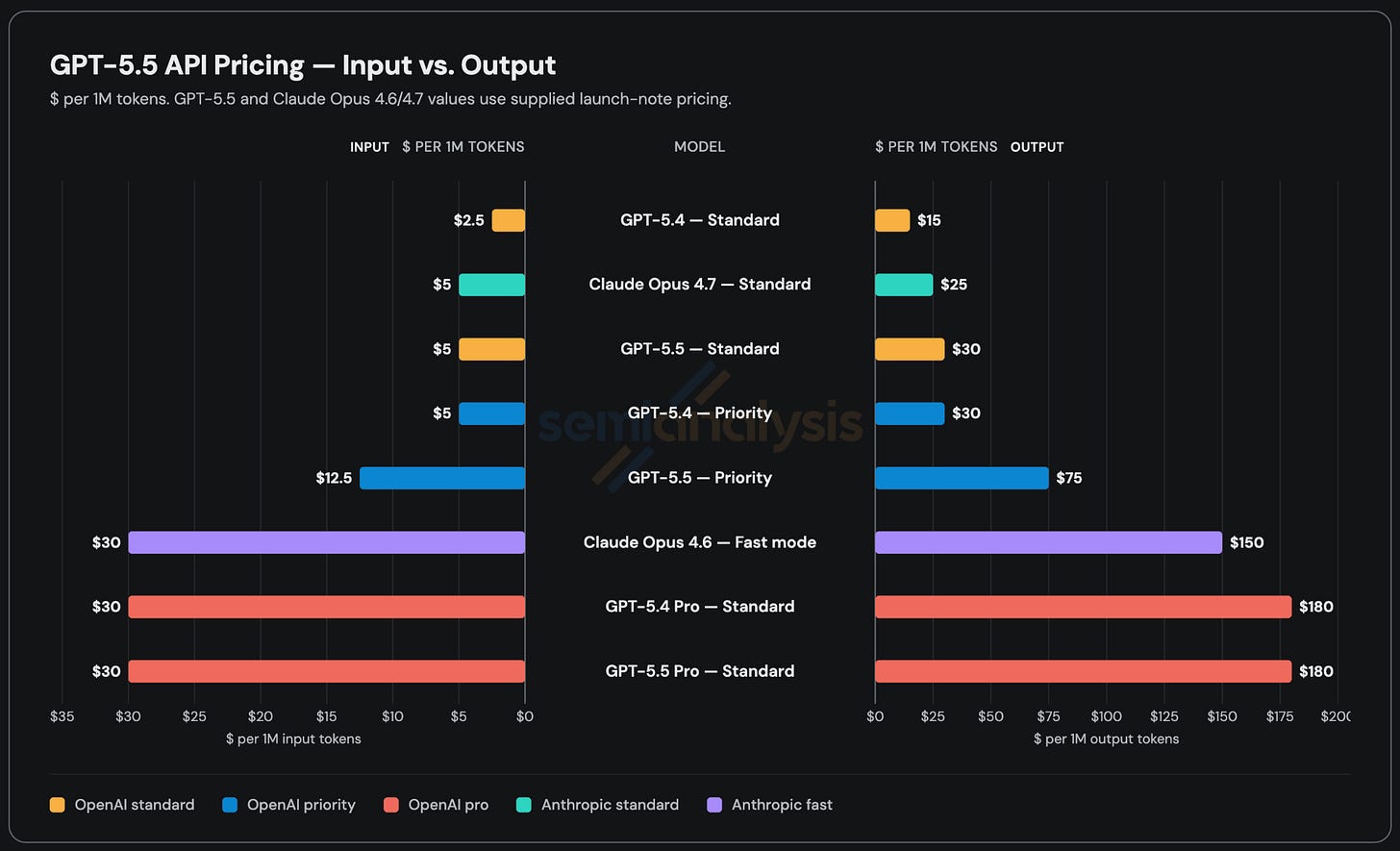
GPT-5.5是首个基于“Spud”公开发布的模型。作为继并不成功的GPT-4.5之后,OpenAI的首个全新基础模型,大家的期待值自然很高。值得注意的是,尽管英伟达和OpenAI都措辞严谨地表示该模型是在“10万张GB200 NVL72集群”上“训练”的,但实际上这仅指后期的强化训练阶段。其基础预训练仍然是在上一代的Hopper架构上完成的。

原文链接:https://newsletter.semianalysis.com/p/the-coding-assistant-breakdown-more
关注微信号:智享开源 关注微博:IMCN开源资讯网 ,可及时获取信息
为你推荐





还没有任何评论,你来说两句吧!